"Suppose there's some connection": Visualizing Character Interactions in Ulysses for Bloomsday 2013
For this year's Bloomsday, Rhonda Armstrong, Regina Higgins, Steven Hoelscher, Pamela Andrews and I collaborated digitally to extend the Ulysses dataset and visualization work begun at THATCamp Prime 2012 (aka Bloomsday 2012). Rhonda, Regina, Steven, and Pamela each thoroughly scoured ten pages of the book to add to our knowledge about the network of character relationships in the novel, and I extended last year's "Wandering Rocks" visualization (off of the data created by Chad Rutkowski and me in 2012), adding in weights showing the "depth" of each character interaction. A huge thank-you to Rhonda, Regina, Steven, and Pamela for their time and effort expanding the public dataset of Ulysses character interactions!
So! You can start immediately below with reading my meta-analysis of the project (basically, how a non-weekend viz project might attack the same problem), jump down to inspect the visualizations, or jump even farther to read the instructions and suggestions I shared with this year's scholars (including an explanation of the "weight" system we used to record a subjective depth to each character interaction).
Related: You can check out last year's Bloomsday visualization work, or read the tutorials (1, 2) for making basic Gephi (infoviz software) visualizations that I created as part of my ACH Microgrant work.
Lessons from the Mini-Project
1. The big caveats with the dataset were caused by my decision to assign volunteers ten-page sections before the actual event: people needed to use the edition of Ulysses they had on hand (which meant assigning increments of ten pages to different people meant different, possibly overlapping, sections of the book were covered), and because some people needed to drop out of participating before Bloomsday, there are gaps in coverage (e.g. pages 1-10 aren't covered). The current dataset covers the following pieces of the book: pages 11-40 and 101-110 (1990 Vintage edition), pages 71-80 (the Project Gutenberg e-text), and pages 81-90 (1961 Modern Library edition)...plus all of "Wandering Rocks".
In retrospect, I probably should have handled dividing pages differently—a better way to handle page numbering: wait until the day of the event to assign pages to those who are still participating, and either require use of the same edition (maybe by scanning and sending out the needed pages to volunteers, so no has the barrier to participation of needing to buy a different edition of Ulysses) or falling back to the non-authoritative Project Gutenberg e-text (easy to copy and paste different sections of the text into emails to the different participants; flaws of this version of the text don't majorly impact our character relationship recording activities). On the other hand, much of the interest in helping out with this project is tied to a desire to (re)read Ulysses, and letting scholars use their preferred edition is important to that reading experience.
Would I do this project again? Absolutely! The participants were amazing collaborators, volunteering their time and effort to expand a public dataset, and having a chance to learn just a bit more about information visualization is always a treat. Next time, though, I'll need to take more time planning out more thorough coverage of a single edition of the work. I'd also spend more time packaging our finished data for use by others (e.g. those with more Gephi chops than me). I did open viewing of our data recording spreadsheet to the public (and am happy to give anyone who wishes to augment the dataset editing capability). You can also check out the CSVs I imported to Gephi (Wandering Rocks spreadsheet, Start of Book spreadsheet), which put the data we gathered in the Google Spreadsheet into Gephi-ingestable form (and fix a few redundant variant-spellings and the like). Given its issues (gaps in page coverage, data from different editions), I didn't actively court anyone to use our data. Next time, with better coverage of the book, I'd reach out to DH tweeps who work more regularly in infoviz to help augment and use the data. But! If you want to work with any of the data or visualizations images, please go ahead! This post, the dataset on GoogleDocs, the two CSVs linked above, and the three visualization images in this post are all CC BY.
2. Visualizations without explanation? (Sacrilege!) Given the holiday and learning nature of this project, we didn't approach it with quite the same end goal as most "proper" visualization projects (by which I mean, scholarship with project-length time and effort, producing an end result of narrated new knowledge). The data creation by the team's scholars was rigorous under the given parameters of a defined but sometimes ambiguous weight spectrum and non-continuous selections from the novel, but it was also a weekend project: looking at the visualizations below, I can confirm some expectations and enjoy getting an unusually broad view of the network of the novel's socializing, but there is much more someone with the time and interest can do!
A full visualization project would benefit from continuous data, or at least data with interesting ways of separating non-continuous sets of pages (e.g. all sections when Stephen is physically present as a way of looking on his effect on social interaction). Some things we'd do with more time to devote to this project:
- We'd analyze the different interaction-type encodings and their placement along a spectrum of relationship intimacy, probably coming up with a better set of weights and a more convincing and clear narrative for each of the interaction types on that scale.
- We'd predict the visualizations' appearances, and analyze how the actual visualization differed and why, as well as discuss other types of new knowledge gained or gainable from the visualization—or what data was missing that could make new knowledge possible.
- We'd also discuss the algorithms used to produce the visualizations, something I'm not (yet!) able to do that is of tantamount importance to scholarly visualization (as with any work that sues a tool, you need to understand how the tool functions to understand its results, its possible biases and blindspots, etc.).
- We could compare the visualization results of multiple layout algorithms, and analyze their different visual arguments or different aspects of character relationships they variously highlight.
That's by no means an exhaustive list, and again, I feel that this kind of dipping ones toes into the waters of a new technique is important—as long as you are aware of what, if any, arguments you're trying to make with your scholarly (or weekend scholar) production.
3. Gephi problems! The current version of Gephi (0.8.2beta) wasn't working on OSX 10.8.4; it loads fine but freezes on the data laboratory screen. I reverted to an older version (0.8.1beta) that works fine, after losing some time trying to get things working.
4. The subjectivity of placing types of relationship interactions along a spectrum (or even just of placing character interactions into "types") could definitely benefit from more debate and detail (see below for a table of the interaction coding we used—I think we came up with it during THATCamp Prime 2012?). The spectrum as it stands has several issues. The sometimes-directionality of the weights made it difficult to know when to record more than one interaction; the codes have both one-way interactions types (X thinks about Y) and two-way interactions (X and Y have a conversation). The interaction code 3, "Omniscient third person narrator (for when two people interact, but it isn't from just one of their viewpoints)", was meant to control for directionality and make "source" and "target" designations meaningful, but didn't end up being useful because interaction codes 4-7 were ambiguous as to direction.
A relatedly subjective issue arose from the choice of node names; for example, the woman's arm that flings a coin to the one-legged sailor clearly belongs to Molly (though maybe not clearly at that point in one's reading)—should that interaction accrue to the "Molly" node, or should a second "her" node be created? Other portions of the book would provide similar problems (e.g. Martha Clifford/Nurse Callan).
The Visualizations
Visualization A, Wandering Rocks Redux. (Click image to view larger.) A visualization of characters interacting with other characters in the "Wandering Rocks" chapter (all pages of chapter covered), with lines weighted by "depth" of the interaction: more intimate encounters have a heavier weight, while "lighter" encounters (e.g. character thinks of another characters or salutes them but does not converse) have lighter connecting lines. See the "Instructions" section below for more on this weighting process. (This visualization augments last year's infoviz by adding weights for each encounter.)
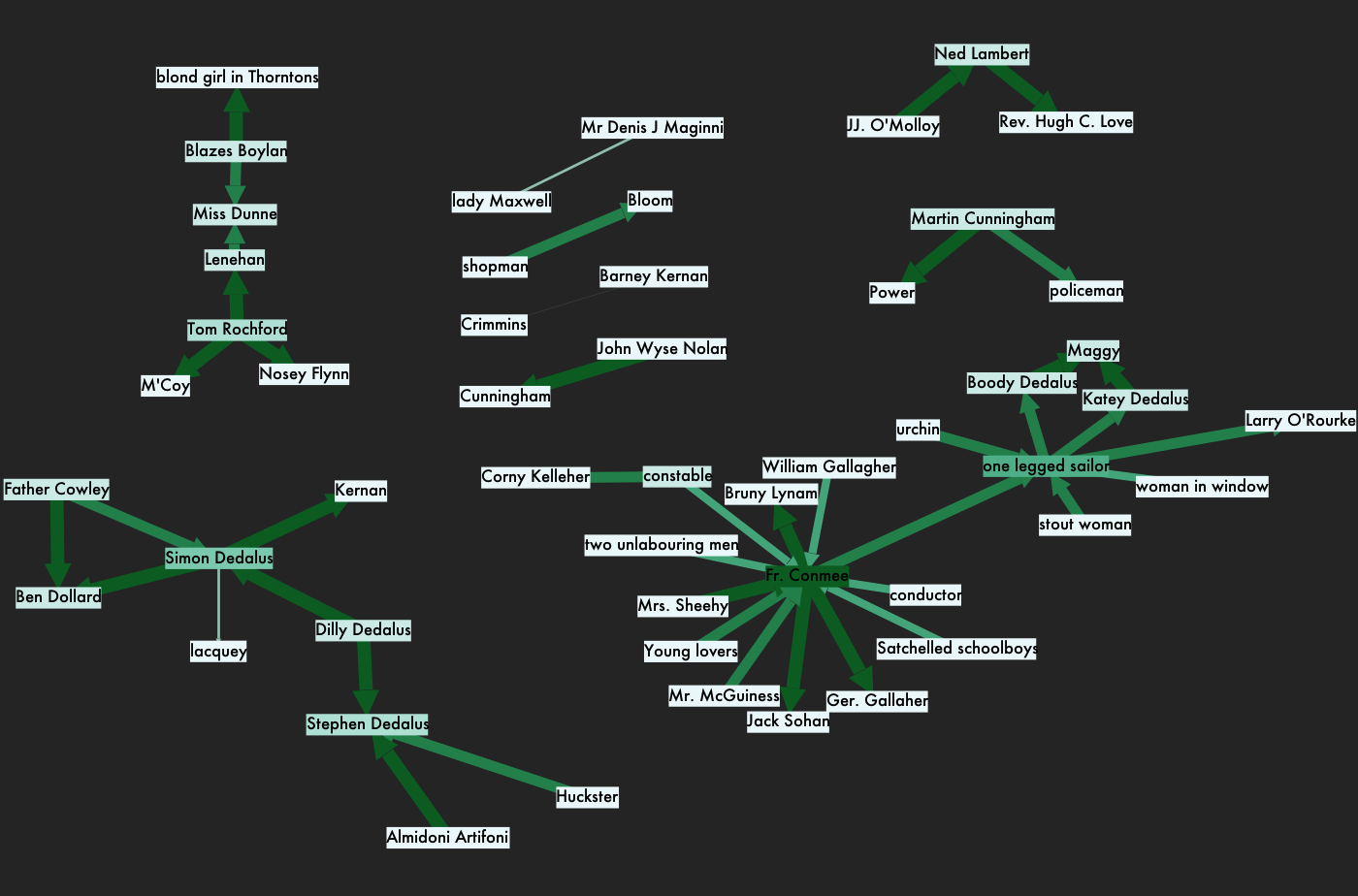
Visualization B, All Characters in Selections from the Beginning of Ulysses. (Click image to view larger.) Below, character interactions drawn from selections near the beginning of the novel: pages 11-40 and 101-110 (1990 Vintage edition), pages 71-80 (the Project Gutenberg e-text), and pages 81-90 (1961 Modern Library edition). Again, lines are weighted by "depth" of the interaction: more intimate encounters have a heavier weight.

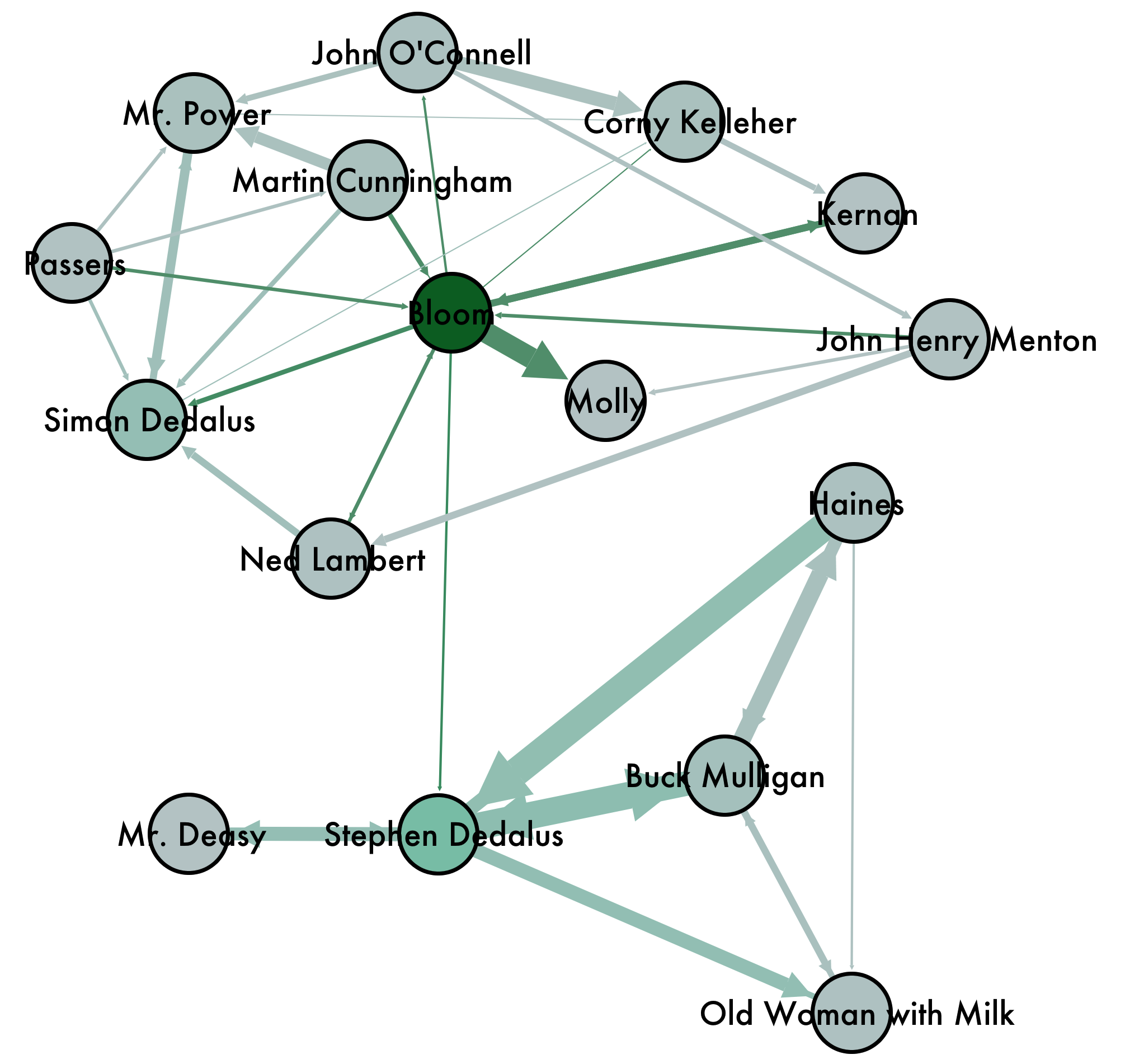
Visualization C, the major socializers in the beginning selections from Ulysses. (Click image to view larger.) Below, a different look at the same dataset (selections from the beginning of the novel). The visualization above shows a node for each character recorded, which makes it less readable. Below, I filtered the dataset to only show those characters who interacted with more than one other person (in Gephi, go to filters > topology > degree range and set how many edges a node must have to appear), giving an easier view of the major socializers in this part of the book (again, lines are weighted with thicker lines showing more intimate interaction).
Instructions for Gathering Data on Character Interactions
The instructions I sent to the other members of the team:
1. Each of you should have access to the Bloomsday InfoViz spreadsheet, where you can see who's been assigned which pages/sections of the book and record your data (check your inbox for a link sent by Google). Please feel very free to take a different or additional set of pages, or do a smaller or larger number of pages than you volunteered for—just make a note on the spreadsheet so we don't do redundant work. Note that the spreadsheet has three different sheets (tabs at the bottom of the page): one for claiming pages, one for recording your data, and one with info on how to code the type of character interaction.
2. There's a bit of difficulty in working together with potentially different editions/page numbers of the book. If you could each let me know the publisher/year of the copy of Ulysses you're using (on the spreadsheet's first sheet), I'll make sure we're not accidentally overlapping [well, that turned out to be too difficult...]. Alternatively or in addition to reading from a print book, you might copy and paste the chunk you want to work on from the Project Gutenberg e-text into a word document; I find this makes skimming for character interactions easier, since you can go through and highlight things. The e-text doesn't have page numbers as far as a I recall, so if you work this way please just let me know the sentence you start and end on.
3. Read or skim for character interactions! (See below for details*.)
4. Record the interactions you read on the spreadsheet. The columns are used as follows:
- This Person [Source]
- Interacts with This Person [Target]: for people speaking to each other, no need to write things twice—that is, when Stephen and Mulligan talk on top of the tower at the start of the book, just record one row with Stephen in either column 1 or 2 and Mulligan the same (the "type of interaction" code will let us know whether it's a directional interaction—that is, person in column 1 is thinking of person in column 2—or a mutual interaction such as a dialogue)
- Type of Interaction: See the third sheet (tab at the bottom of the spreadsheet that says "Codes for Character Interactions" for info on how to code types of interaction here
- Episode or Page Numbers: Note which episode or range of page numbers in which this interaction occurs (no need to mark specific page number; you can just record e.g. that something occurred in your range of pages 80-99)
- Edition (Publisher, Date) of Book Used
- Who Did This Work?: Your name (so we can credit you for your contribution!)
* So what's an interaction?
- We're treating an "interaction" as some type of interchange between two characters; if more than two characters are interacting, please break these into pairs of two characters that represent all interactions going on and record the two names with one name in column 1 and the other name in column 2 (this will let our software draw lines between each pairing of characters). For example, when Haines, Mulligan, and Stephen eat breakfast together in the first chapter of the book, you'd add three rows: Haines and Mulligan, Haines and Stephen, Mulligan and Stephen. Note that for people speaking to each other, no need to write things twice—that is, when Stephen and Mulligan talk on top of the tower at the start of the book, just record one row with Stephen in either column 1 or 2 and Mulligan in the other column; the "type of interaction" code will let us know whether it's a directional interaction—that is, person in column 1 is thinking of person in column 2—or a mutual interaction such as a dialogue.
- Deciding when interactions between characters start and end will have to be a bit subjective—just use your best judgement. An "interaction" is a chunk of communication such as a dialogue, a speech directed at one or more specific characters, or thinking about an absent character; "chunk" means that we'll think of an interaction as ending (allowing a new one that occurs later to be recorded as a separate interaction) when communication ends, other events intervene, or the thinker starts thinking about something or someone else. for example: Does Bloom think about Molly while walking along the street, and then think about other stuff, and then think about Molly again? I'd count that as two interactions. Among other interactions in the opening chapter ("Telemachus"), Stephen and Mulligan talk on the roof of the tower, then Stephen is left alone (and thinks about Mulligan), and then Stephen and Mulligan have a different interaction (breakfast with Haines) downstairs; I'd count those as three different interactions.
- You don't need to spend time agonizing over where interactions end and what type of interaction took place—just use your best judgement and have fun! If you're really unsure, leave a brief note in the "comments" column to the right of the row with the questionable interaction and I can check it out. The idea is to get as rich a recording of interactions as possible (e.g. to get a sense of how often thoughts of Molly invade Bloom's day) without, for example, recording every line of a dialogue as a separate interaction.
Codes for Character Interactions
Coded interactions by number along a highly subjective spectrum of relationship depth (see "Lessons" section above for some of the issues that rose from this coding):
| Coding for Type of Character Interaction | Code to Use in Type of Interaction Column |
| Character thinking of another character | 1 |
| Character observing another character | 2 |
| Omniscient third person narrator (for when two people interact, but it isn't from just one of their viewpoints) | 3 |
| Character acknowledging another character without speaking (tip of the hat, nod, etc.) | 4 |
| Character voicing salutation to another character or other extremely brief interchange | 5 |
| Character entering into conversation with another character | 6 |
| Character having intimate contact with another character | 7 |
Happy (belated) Bloomsday!